Computer Vision in Python/Go

Image classification using neural networks with Python
MNIST dataset
This project utilizes the The Modified National Institute of Standards and Technology (MNIST) dataset which comprises of 60 thousand training observations and 10 thousand test observations of handwritten digits.
Due to the complexity of imaging data, connectionist network models or neural networks have been gaining significant interest in recent years. Python machine learning packages sklearn and keras have been especially useful for specifying neural network architectures. This project aims to understand how connectionist models improve testing accuracy by varying the number of nodes in the hidden ’layer’ between one (actually not connectionist), two and 128 nodes. Expectedly, neural network models with 128 nodes in the hidden layer performed the best with 97% testing accuracy compared to 31%, 67% for the single node and double node models respectively. Understand the improvement in accuracy with these plots of the class distributions of the activation values in the hidden layer.
For a single node in the hidden layer (equivalent to logistic regression), we see some overlap:
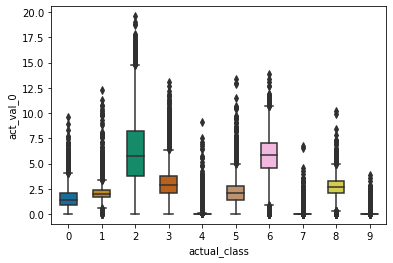
Increasing the number of nodes in the hidden layer by one, we see better seperation between the classes:
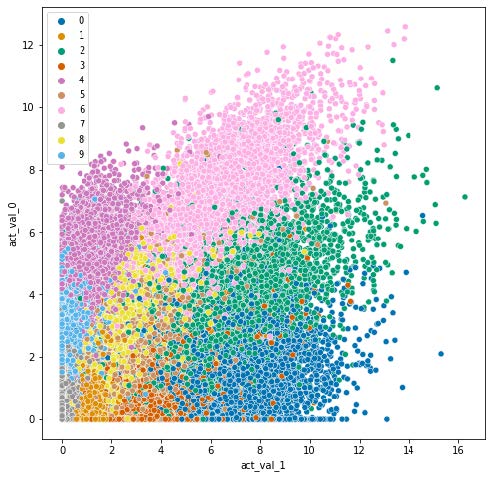
See my report for further details. Also, see each experiment for each of the models (single node , double node , many nodes ), as well as preprocessing inputs using principal component analysis (PCA) or ranked inputs from a random forest analysis.
CIFAR-10 dataset
The growth of the mobile ecosystem has led to an unprecedented increase in the amount of digital imaging data. Alongside the considerable increase in computing power, deep learning neural networks are becoming an attractive option for computer vision applications in image classification. This study explores different network topologies and hyperparameters for traditional and convolutional neural networks using the CIFAR-10 dataset (Canadian Institute of Advanced Research) of 60,000 images and 10 categories. The best performing model had a testing accuracy score of 77% and was with 3 hidden convolutional layers in a stacked topology with a fully connected layer and dropout regularization. Overall, convolutional neural network models performed better than traditional neural networks suggesting the suitability of convolution for computer vision applications. However, a key drawback is the high processing time in training models with convolutional layers.
See my report for further details. Also, see the Jupyter notebooks for each experiment here:
| Experiment number | Description |
|---|---|
| 1 | 2 layer deep neural network with 2000 neurons |
| 2 | 3 layer deep neural network with 2000 neurons |
| 3 | 2 layer deep convolutional neural network with 128, 256 neurons |
| 4 | 3 layer deep convolutional neural network with 128, 256, 512 neurons |
| 5 | 2 layer deep neural network with 2000 neurons and 0.3 dropout regularization |
| 6 | 3 layer deep neural network with 2000 neurons and 0.3 dropout regularization |
| 7 | 2 layer deep convolutional neural network with 128, 256 neurons and 0.3 dropout regularization |
| 8 | 3 layer deep convolutional neural network with 128, 256, 512 neurons and 0.3 dropout regularization |
| 9 | 2 layer deep convolutional neural network with 128, 256 neurons and 0.6 dropout regularization |
| 10 | 3 layer deep convolutional neural network with 128, 256, 512 neurons, 0.3 dropout regularization and a fully connected classification layer with 100 neurons |
Image classification using random forests with Go
This project creates a demo towards implementing a data engineering pipeline from image capture to recognition for an integrated application using purely Go. For this demonstration, image classification is performed using Go’s randomForest package employed on MNIST dataset using the GoMNIST driver. Results are compared using an isolation forest (go-iforest) trained on all of the test observations. For information about isolation forests, see an earlier post comparing Go with Python/R under “Identifying anomalies in MNIST”. The best-performing model utilized 1000 trees and had 96% accuracy on the hold-out test dataset with comparable accuracy for each digit. The average anomaly score was expectedly higher for the misclassified images. Misclassified images from the test set are printed using Go’s image package.
To run locally, download or git clone this project:
| |
Images are printed in a new directory ‘imagesout’ with the name coressponding to imageID, predicted digit, true digit and a boolean score for whether or not it is classified as anomalous. A csv file titled ‘goScores.csv’ is also created with information for all of the images and an additional column for the anomaly score.
See my Github repository for further details.
References
Sambamoorthi, Nethra. “Computer Vision Part 1”. MSDS 458: Artificial Intelligence and Deep Learning. Course at Northwestern University, Chicago, IL, October 9, 2022. https://github.com/aimlfacnwu/MSDS_458_Fall2022/tree/master/MSDS458_Assignment_01
Sambamoorthi, Nethra. “Computer Vision Part 1”. MSDS 458: Artificial Intelligence and Deep Learning. Course at Northwestern University, Chicago, IL, October 23, 2022. https://github.com/aimlfacnwu/MSDS_458_Fall2022/tree/master/MSDS458_Assignment_02
Miller, Tom. “Data Cleaning, Frames and Pipelines,”. MSDS 431: Data Engineering with Go. Course at Northwestern University, Chicago, IL, June 19, 2023.